一、设计目标
- Redis分布式布隆过滤器。
- 用户使用透明。(无需关心内部路由、存储细节)
- 简单易用(如同使用本地布隆过滤器)。
- 支持多种API和批量操作。
- 支持多种hash函数。
- 高性能、低错误率。
二、基本架构
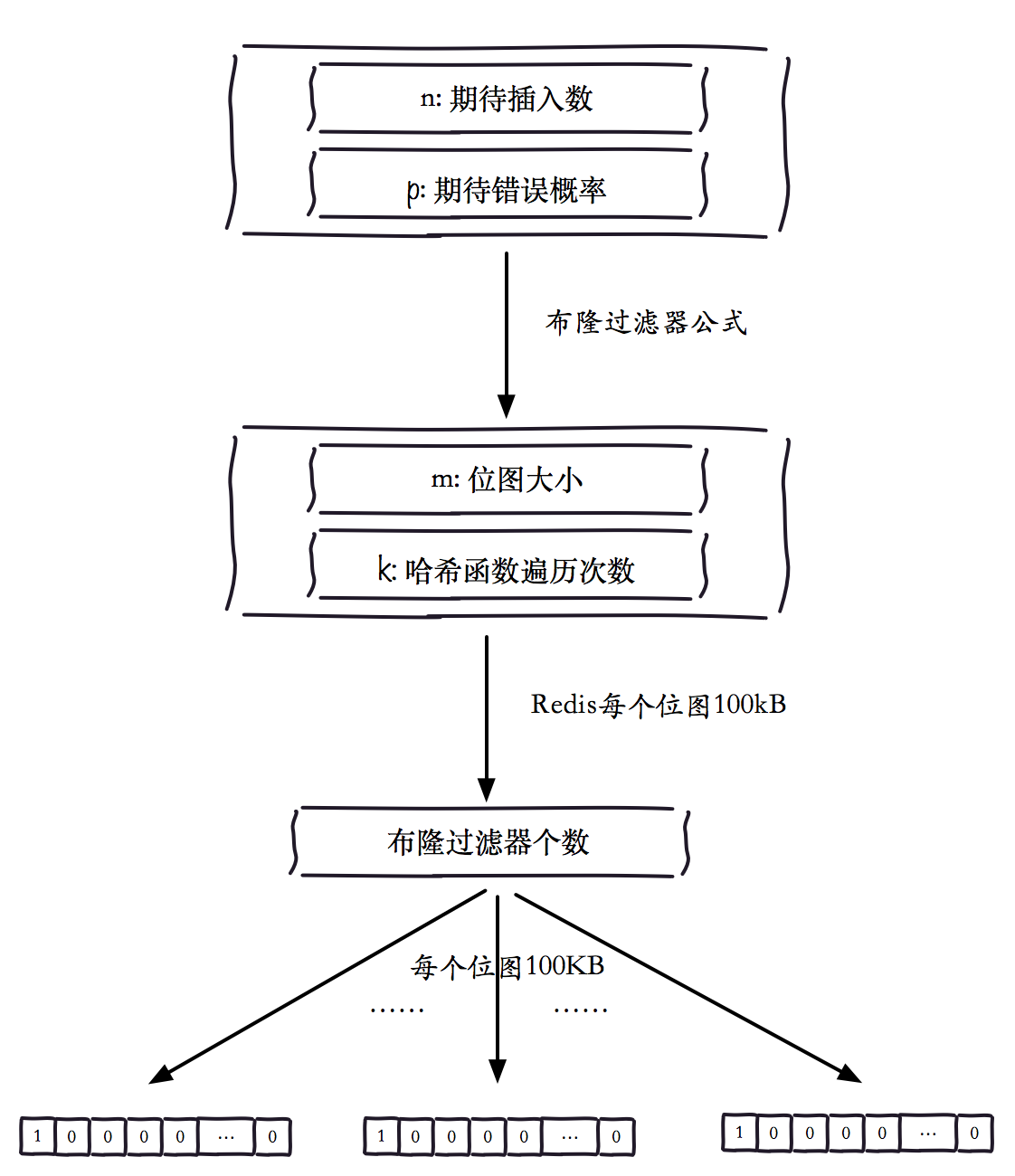
- 两个输入参数:期望插入个数、期望错误概率
- 布隆过滤器概率公式计算两个参数:总位图大小、哈希函数迭代次数
- 每个Redis的位图设置为100KB:计算布隆过滤器的个数
- 根据元素的哈希值,将添加和是否包含请求路由到Redis各个位图上
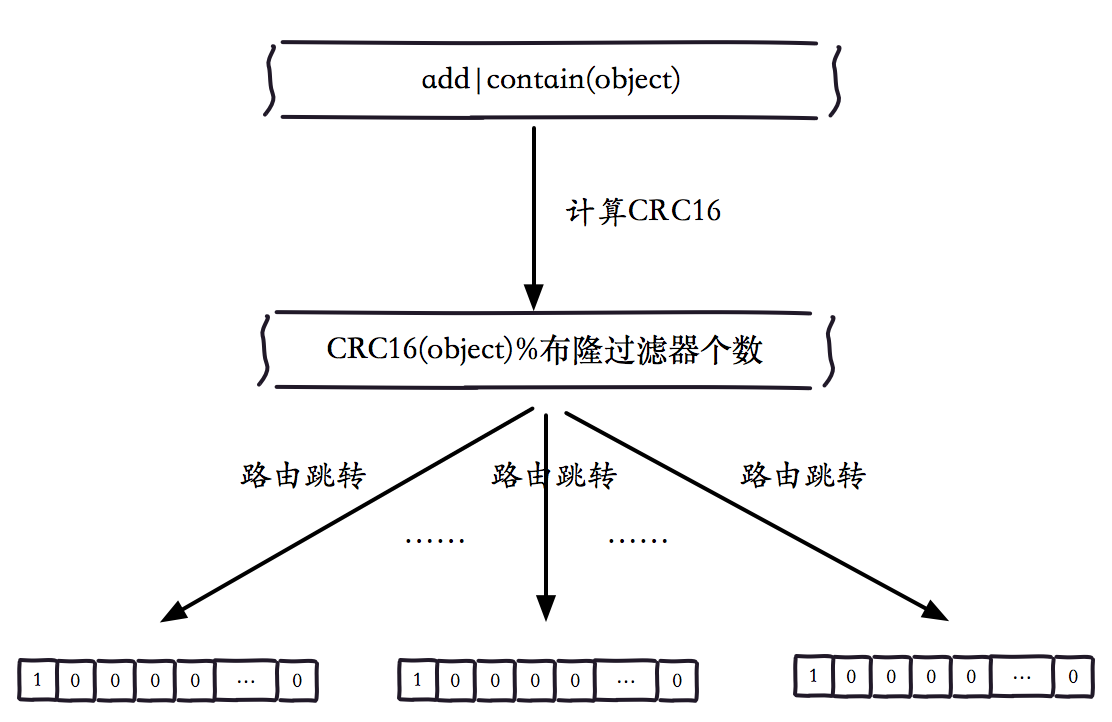
例如 add(“element-100”)操作的伪代码如下:
|
|
三、快速使用
该功能内置在CacheCloud客户端,无需引入其他依赖
|
|
快速使用:
|
|
四、API说明
1. 参数说明
|
|
必需参数:
| 参数名 | 含义 | 说明 |
|---|---|---|
| pipelineCluster | redisCluster客户端 | 可以通过appid构造 |
| name | 布隆过滤器名 | 唯一 |
| expectedInsertions | 预计插入的条数 | 最大不能超过1000亿 |
| falseProbability | 预计错误率 | 有关布隆过滤器错误率,可以查看维基百科 |
可选参数:
| 参数名 | 含义 | 说明 | 默认值 |
|---|---|---|---|
| HashFunction hashFunction | 哈希算法 | 目前支持CRC32、Murmur2、Murmur3三种算法(支持扩展)。 | 使用Murmur3哈希算法 |
| int childBloomMaxSize | 子布隆过滤器位数 | 1千万(约1MB) |
例如使用方法如下
|
|
2. 相关API说明
(1) 添加
|
|
(2) 批量添加
|
|
(3) 查看包含
|
|
(4) 批量查看包含
|
|
(5) 清除布隆过滤器
|
|
(6) 布隆过滤器几个参数
|
|
五、相关测试
|
|
| 测试插入数据量 | bloomfilter分片大小 | 批量提交条数 | 耗时 | QPM | 占用空间/对象数 | 网络流量 |
|---|---|---|---|---|---|---|
| 4000w(4个线程并行) | 1000万(1MB) | 5000 | 24分钟 | 2100w/min 35w/s |
3.47G/1920个 | 1100k |
| 4000w(4个线程并行) | 5000w(5MB) | 5000 | 12分钟 | 4200w/min 70w/s |
3.03G/396个 | 2300k |
| 4000w(4个线程并行) | 1个亿(10MB) | 5000 | 11分钟 | 4750w/min 80w/s |
3.01G/193个 | 2600K |
初步结论
|
|
六、相关改进
- 支持多种Redis类型
- Murmur3是耗时和错误率较低布隆过滤器函数(查的一组测试数据),具体有待测试。